OpenSchema takes care of selecting what to say and structuring the selected information. This is achieved by going executing an augmented transition network (ATN), which for the purposes of this software package it is a grammar for a regular language (think regular expressions) over discourse predicates defined also as part of the schema itself.
The process of traversing the ATN is guided by a focus stack that keeps track of the objects mentioned, building a coherent discourse (OpenSchema provides three strategies for this process, a simple focus chooser that implements McKeown 1985 heuristics, a greedy chooser and a random chooser).
The schema is invoked with a set of frames and initial parameters that map variable names to frames nodes. As the instantiation process progresses, the different predicates might be invoked with free variables, which are bound based on the predicate constraints.
A frame is a hierarchical attribute-value pair dictionary, with two distinguished keys, ID and type. They constitute the basic data structure both for inputs and outputs of the OpenSchema planner.
A predicate involves variables, constraints over the variables and an output frame that contain the clause to be added to the output text. This clause is still very abstract, it contains only the information need by the sentence planner (which will aggregate it into full sentences and also decide which words or pronouns to use for each of the concepts referred) and the surface realiser (which will transform the full sentence descriptions into actual textual strings).
Besides the predicates and the regular grammar operators, the schema can also contain special markers to indicate aggregation and paragraph boundaries. These are hints to the sentence planner that only sentences within these boundaries should be aggregated together.
OpenSchema has a domain-specific language for defining schemata. It uses whitespace to determine the structural binding of the different elements. Semi-colons mark comments, till the end of the line.
At the top indentation level, there are two types of structres: predicate and schema.
The predicates have a name and then three sections: variables, properties and output, containing the variables, constraints and the output clause. The variables can required (marked with req, meaning the predicate won't instantiate unless that variable is provided) and also one variable can be marked as the default focus (marked with def). The properties that can be defined so far are equality (or not) and whether a frame is under a certain ontological type. More properties are expected to be defined (see the Roadmap). The output section is a hierarchical attribute-value matrix, defined by indentation.
predicate pred-person
variables
req def person : c-person
occupation : c-occupation
properties ; properties that the variables have to hold
occupation == person.occupation
output
template "{{name-first}} {{name-last}} is a {{occupation}}. "
name-first person.name.first-name
name-last person.name.last-name
occupation occupation.#TYPE
; preds
pred attributive
pred0 person
pred1 occupation
; ... other predicates ...
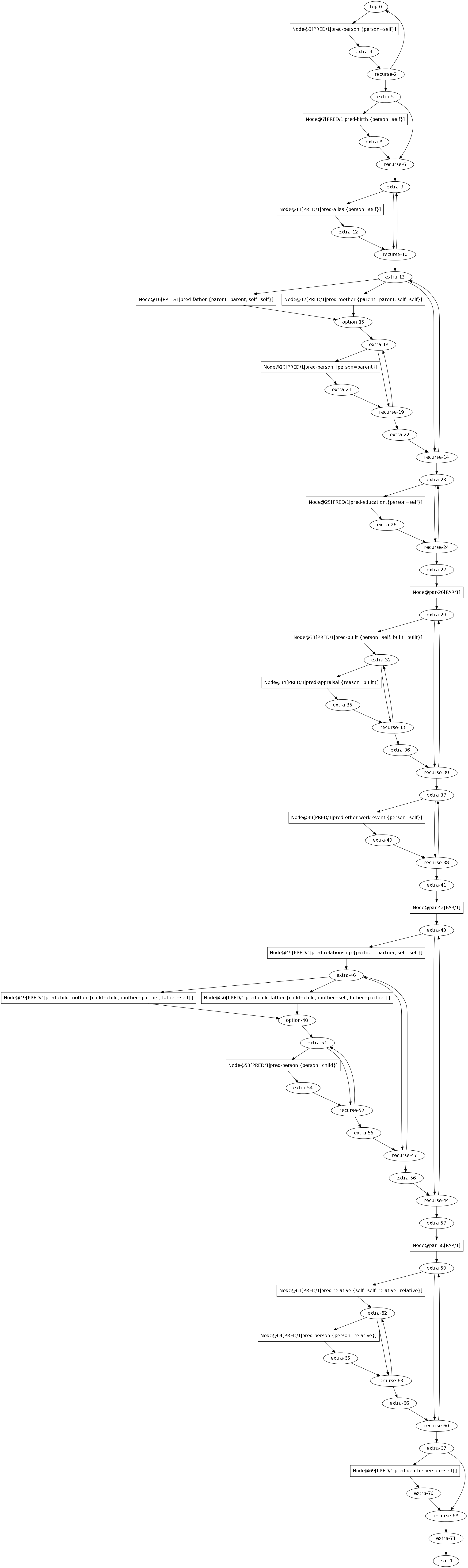
schema biography(self: c-person)
; name of the schema 'biography'
; self is the person the bio is about, required
; first paragraph, the person
plus
pred-person(person|self)
optional
pred-birth(person|self)
star ; zero or more aliases
pred-alias(person|self)
star ; zero or more parents
choice
pred-father(self|self,parent|parent)
pred-mother(self|self,parent|parent)
star
pred-person(person|parent)
star ; zero or more education
pred-education(person|self)
paragraph-boundary
Schemata can be defined using the DSL described in the previous section or directly as an XML file complying with the OpenSchema.xsd. Internally the DSL is transformed to a XML file while being loaded.
Currently, the system can take inputs as RDF graphs (the ID being the name of the resource and the type a special TYPE verb) or CSV files (of the form of NT triples).
Programmatically, the instantiate method in the OpenSchemaPlanner class takes a FrameSet, which is an interface that can be made concrete with data structures as needed by the application.
The output of the OpenSchemaPlanner is a DocumentPlan, which contains a list of paragraph, each of which is a list of aggregation segments. Finally, an aggregation segment is a list of clauses, where each clause is a hierarchical attribute-value matrix, represented as a java Map from Strings to Object.
For a complete example, look at net.sf.openschema.demo.TemplateSystem. It instantiates a schema and then searches for a "template" key in each clause, instantiating them using {{ Handlebars.java }} to produce sentences. (The dependency on handlebars is for the demo template system, not for OpenSchema in general.)
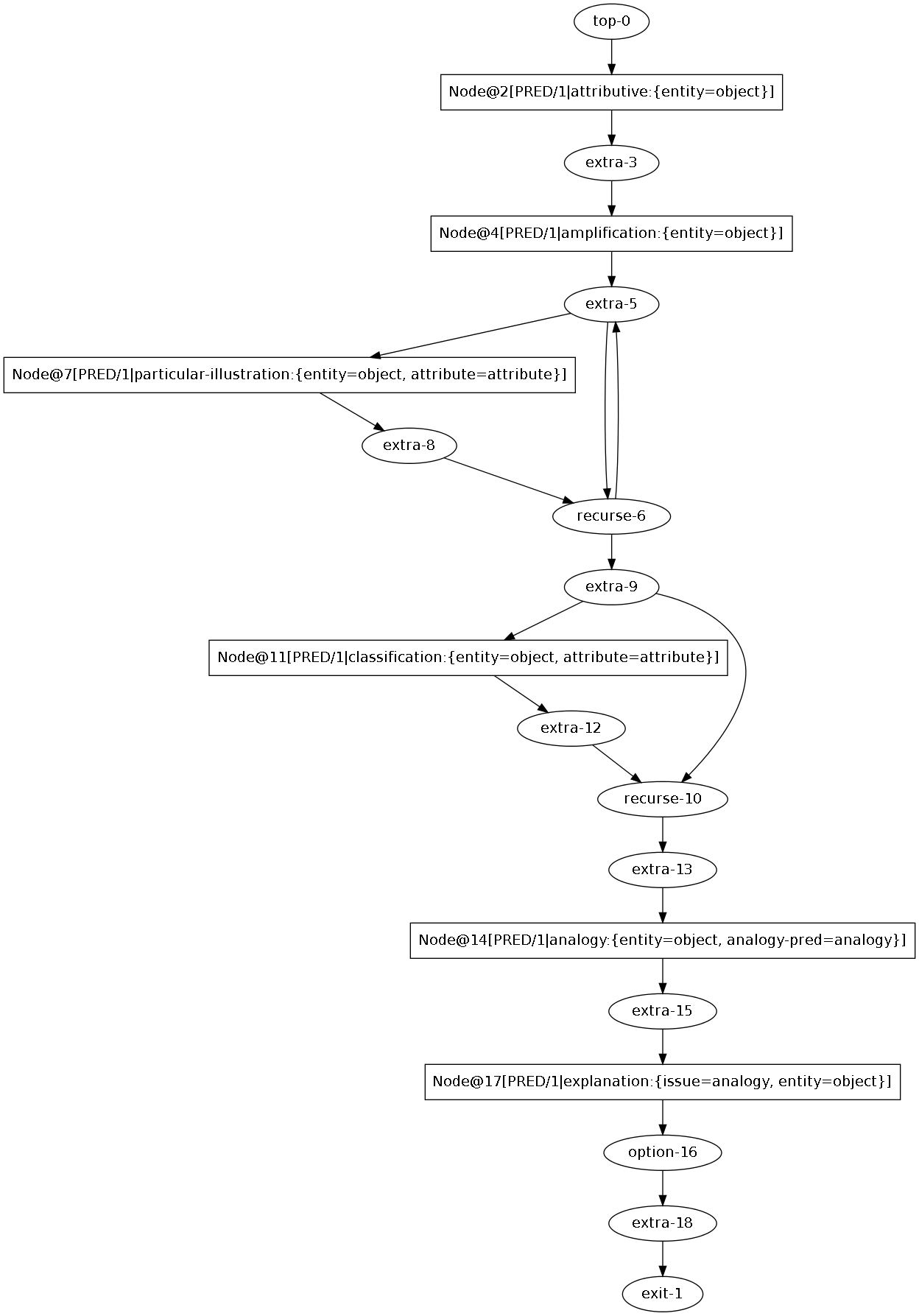
The provided examples, the biography schema and the attributive schema are compiled as this graph and this graph, respectively.
Hosted by:
{kind=link}
{kind=link}